Introduction
In this post, we will look into the Fed Funds cycles and evaluate asset class performance during loosening and tightening of monetary policy.
Python Functions
Here are the functions needed for this project:
- calc_fed_cycle_asset_performance: Calculates the performance of various asset classes during the Fed Funds cycles.
- df_info: A simple function to display the information about a DataFrame and the first five rows and last five rows.
- df_info_markdown: Similar to the
df_infofunction above, except that it coverts the output to markdown. - export_track_md_deps: Exports various text outputs to markdown files, which are included in the
index.mdfile created when building the site with Hugo. - load_data: Load data from a CSV, Excel, or Pickle file into a pandas DataFrame.
- pandas_set_decimal_places: Set the number of decimal places displayed for floating-point numbers in pandas.
- plot_bar_returns_ffr_change: Plot the bar chart of the cumulative or annualized returns for the asset class along with the change in the Fed Funds Rate.
- plot_timeseries: Plot the timeseries data from a DataFrame for a specified date range and columns.
- plot_scatter_regression_ffr_vs_returns: Plot the scatter plot and regression of the annualized return for the asset class along with the annualized change in the Fed Funds Rate.
- yf_pull_data: Download daily price data from Yahoo Finance and export it.
Data Overview
Acquire & Plot Fed Funds Data
First, let’s get the data for the Fed Funds rate (FFR):
| |
This gives us:
| |
The first 5 rows are:
| DATE | FEDFUNDS | FedFunds_Change |
|---|---|---|
| 2004-11-30 00:00:00 | 0.0193 | nan |
| 2004-12-31 00:00:00 | 0.0216 | 0.0023 |
| 2005-01-31 00:00:00 | 0.0228 | 0.0012 |
| 2005-02-28 00:00:00 | 0.0250 | 0.0022 |
| 2005-03-31 00:00:00 | 0.0263 | 0.0013 |
The last 5 rows are:
| DATE | FEDFUNDS | FedFunds_Change |
|---|---|---|
| 2025-06-30 00:00:00 | 0.0433 | 0.0000 |
| 2025-07-31 00:00:00 | 0.0433 | 0.0000 |
| 2025-08-31 00:00:00 | 0.0433 | 0.0000 |
| 2025-09-30 00:00:00 | 0.0422 | -0.0011 |
| 2025-10-31 00:00:00 | 0.0409 | -0.0013 |
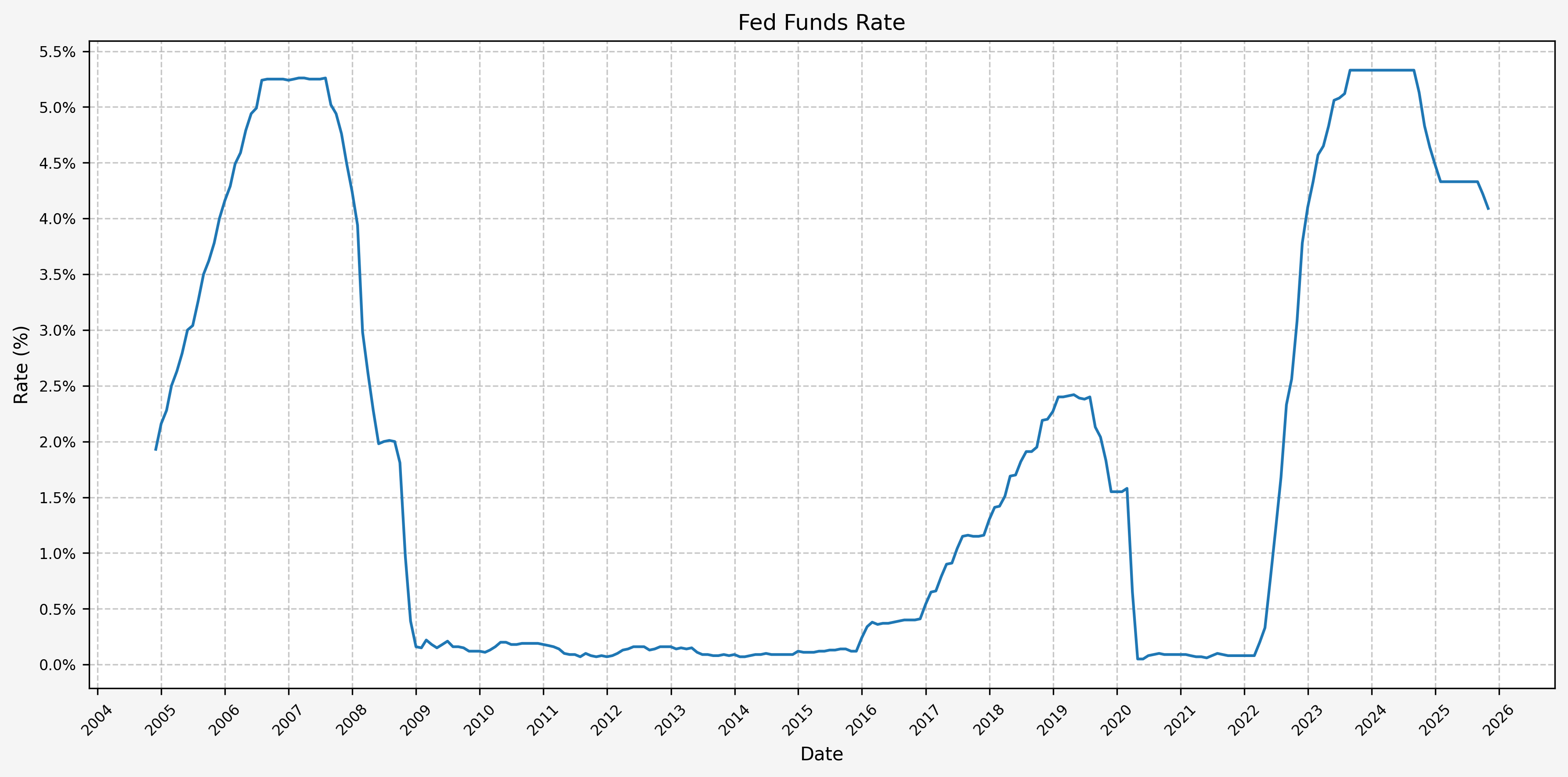
We can then generate several useful visual aids (plots). First, the FFR from the beginning of our data set (11/2004):
| |
And then the change in FFR from month-to-month:
| |
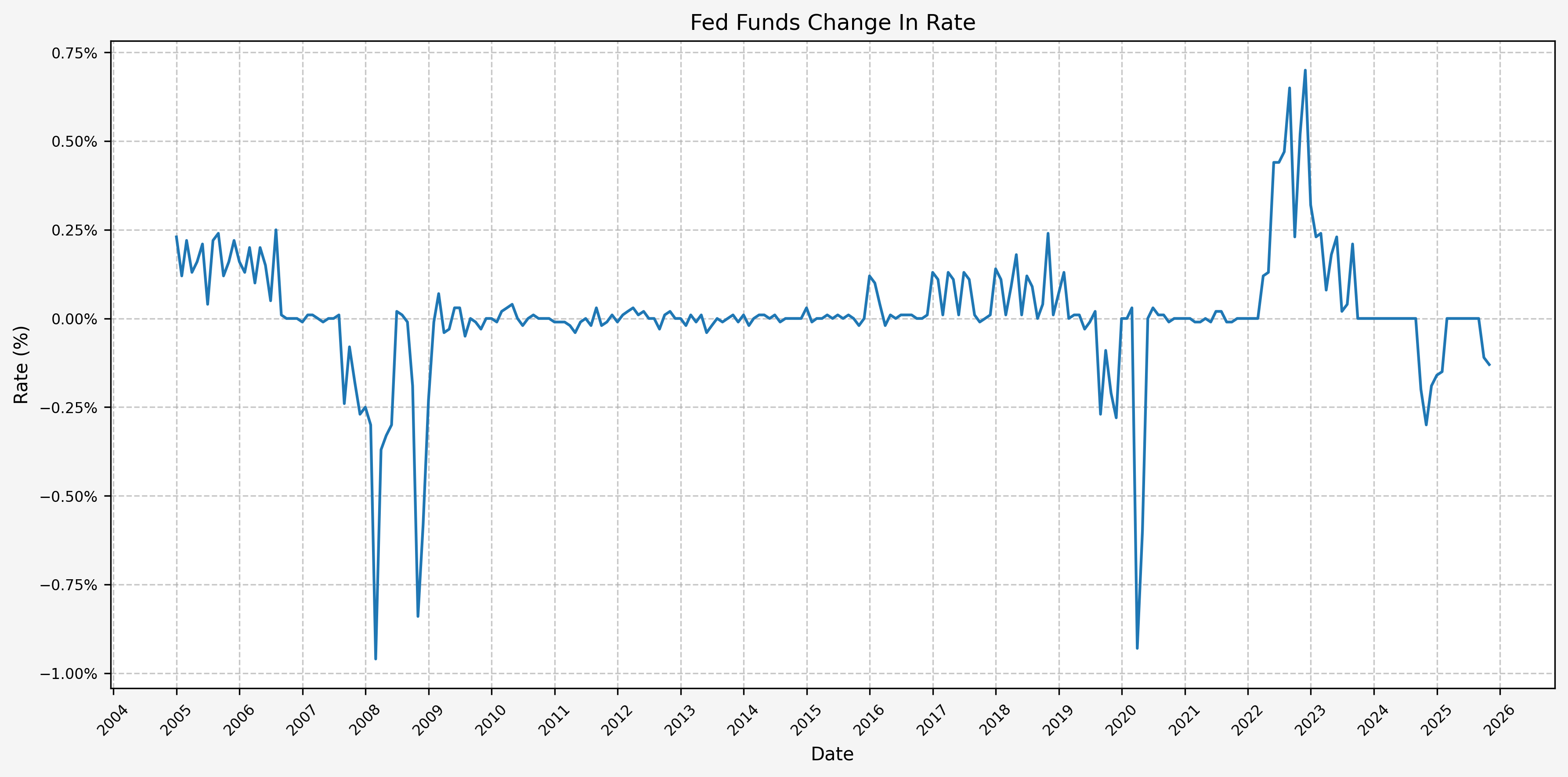
This plot, in particular, makes it easy to show the monthly increase and decrease in the FFR, as well as the magnitude of the change (i.e. slow, drawn-out increases or decreases or abrupt large increases or decreases).
Define Fed Policy Cycles
Next, we will define the Fed policy tightening and loosening cycles. This is done via visual inspection of the FFR plot and establishing some timeframes for when the cycles started and ended. Here’s the list of cycles:
| |
And here’s the list of total change in the FFR corresponding to each cycle:
| |
| Cycle | FedFunds_Change | |
|---|---|---|
| 0 | Cycle 1 | 0.0331 |
| 1 | Cycle 2 | 0.0002 |
| 2 | Cycle 3 | -0.0510 |
| 3 | Cycle 4 | -0.0004 |
| 4 | Cycle 5 | 0.0228 |
| 5 | Cycle 6 | 0.0000 |
| 6 | Cycle 7 | -0.0235 |
| 7 | Cycle 8 | 0.0003 |
| 8 | Cycle 9 | 0.0525 |
| 9 | Cycle 10 | 0.0000 |
| 10 | Cycle 11 | -0.0124 |
Return Performance By Fed Policy Cycle
Moving on, we will now look at the performance of three (3) asset classes during each Fed cycle. We’ll use SPY as a proxy for stocks, TLT as a proxy for bonds, and GLD as a proxy for gold. These datasets are slightly limiting due to the availability of all 3 starting in late 2004, but will work for our simple exercise.
Stocks (SPY)
First, we pull data with the following:
| |
And then load data with the following:
| |
Gives us the following:
| |
The first 5 rows are:
| Date | Close | High | Low | Open | Volume | Monthly_Return |
|---|---|---|---|---|---|---|
| 2004-11-30 00:00:00 | 79.83 | 80.07 | 79.66 | 79.90 | 53685200.00 | nan |
| 2004-12-31 00:00:00 | 82.23 | 82.77 | 82.19 | 82.53 | 28648800.00 | 0.03 |
| 2005-01-31 00:00:00 | 80.39 | 80.45 | 80.08 | 80.25 | 52532700.00 | -0.02 |
| 2005-02-28 00:00:00 | 82.07 | 82.53 | 81.67 | 82.43 | 69381300.00 | 0.02 |
| 2005-03-31 00:00:00 | 80.57 | 80.91 | 80.51 | 80.73 | 64575400.00 | -0.02 |
The last 5 rows are:
| Date | Close | High | Low | Open | Volume | Monthly_Return |
|---|---|---|---|---|---|---|
| 2025-06-30 00:00:00 | 616.14 | 617.51 | 613.34 | 615.67 | 92502500.00 | 0.05 |
| 2025-07-31 00:00:00 | 630.33 | 638.08 | 629.03 | 637.69 | 103385200.00 | 0.02 |
| 2025-08-31 00:00:00 | 643.27 | 646.05 | 641.36 | 645.68 | 74522200.00 | 0.02 |
| 2025-09-30 00:00:00 | 666.18 | 666.65 | 661.61 | 662.93 | 86288000.00 | 0.04 |
| 2025-10-31 00:00:00 | 682.06 | 685.08 | 679.24 | 685.04 | 87164100.00 | 0.02 |
Next, we can plot the price history before calculating the cycle performance:
| |
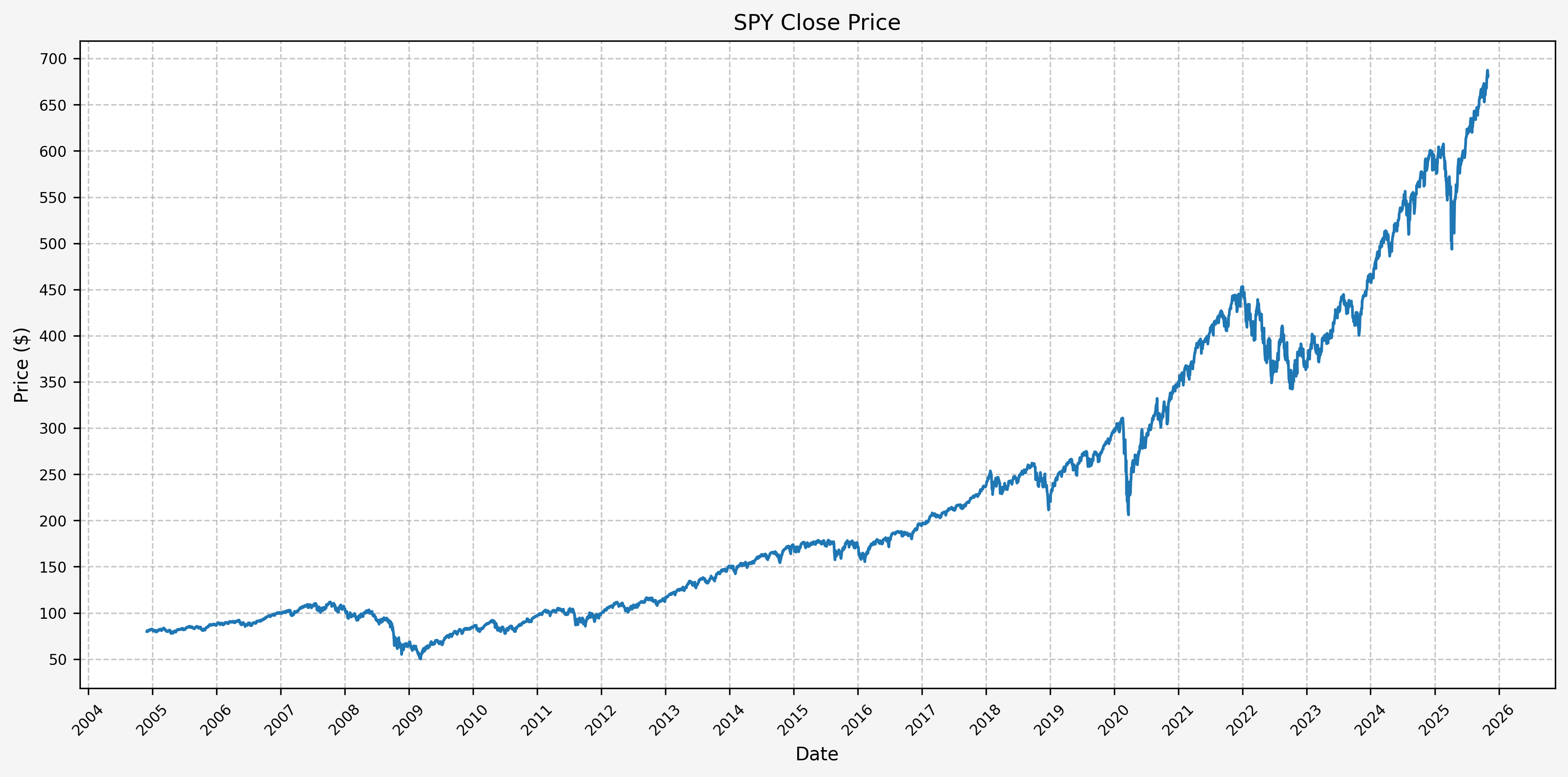
Next, we will calculate the performance for SPY based on the pre-defined Fed cycles:
| |
Which gives us:
| Cycle | Start | End | Months | CumulativeReturn | CumulativeReturnPct | AverageMonthlyReturn | AverageMonthlyReturnPct | AnnualizedReturn | AnnualizedReturnPct | Volatility | FedFundsChange | FedFundsChange_bps | FFR_AnnualizedChange | FFR_AnnualizedChange_bps | Label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Cycle 1 | 2004-11-01 | 2006-07-01 | 20 | 0.11 | 11.32 | 0.01 | 0.59 | 0.07 | 6.64 | 0.08 | 0.03 | 331.00 | 0.02 | 198.60 | Cycle 1, 2004-11-01 to 2006-07-01 |
| 1 | Cycle 2 | 2006-07-01 | 2007-07-01 | 12 | 0.20 | 20.36 | 0.02 | 1.57 | 0.20 | 20.36 | 0.07 | 0.00 | 2.00 | 0.00 | 2.00 | Cycle 2, 2006-07-01 to 2007-07-01 |
| 2 | Cycle 3 | 2007-07-01 | 2008-12-01 | 17 | -0.39 | -38.55 | -0.03 | -2.67 | -0.29 | -29.09 | 0.19 | -0.05 | -510.00 | -0.04 | -360.00 | Cycle 3, 2007-07-01 to 2008-12-01 |
| 3 | Cycle 4 | 2008-12-01 | 2015-11-01 | 83 | 1.67 | 167.34 | 0.01 | 1.28 | 0.15 | 15.28 | 0.15 | -0.00 | -4.00 | -0.00 | -0.58 | Cycle 4, 2008-12-01 to 2015-11-01 |
| 4 | Cycle 5 | 2015-11-01 | 2019-01-01 | 38 | 0.28 | 28.30 | 0.01 | 0.70 | 0.08 | 8.19 | 0.11 | 0.02 | 228.00 | 0.01 | 72.00 | Cycle 5, 2015-11-01 to 2019-01-01 |
| 5 | Cycle 6 | 2019-01-01 | 2019-07-01 | 6 | 0.18 | 18.33 | 0.03 | 2.95 | 0.40 | 40.01 | 0.18 | 0.00 | 0.00 | 0.00 | 0.00 | Cycle 6, 2019-01-01 to 2019-07-01 |
| 6 | Cycle 7 | 2019-07-01 | 2020-04-01 | 9 | -0.11 | -10.67 | -0.01 | -1.10 | -0.14 | -13.96 | 0.19 | -0.02 | -235.00 | -0.03 | -313.33 | Cycle 7, 2019-07-01 to 2020-04-01 |
| 7 | Cycle 8 | 2020-04-01 | 2022-02-01 | 22 | 0.79 | 79.13 | 0.03 | 2.78 | 0.37 | 37.43 | 0.16 | 0.00 | 3.00 | 0.00 | 1.64 | Cycle 8, 2020-04-01 to 2022-02-01 |
| 8 | Cycle 9 | 2022-02-01 | 2023-08-01 | 18 | 0.04 | 4.18 | 0.00 | 0.40 | 0.03 | 2.77 | 0.21 | 0.05 | 525.00 | 0.03 | 350.00 | Cycle 9, 2022-02-01 to 2023-08-01 |
| 9 | Cycle 10 | 2023-08-01 | 2024-08-01 | 12 | 0.22 | 22.00 | 0.02 | 1.75 | 0.22 | 22.00 | 0.15 | 0.00 | 0.00 | 0.00 | 0.00 | Cycle 10, 2023-08-01 to 2024-08-01 |
| 10 | Cycle 11 | 2024-08-01 | 2025-11-30 | 15 | 0.26 | 25.72 | 0.02 | 1.59 | 0.20 | 20.09 | 0.11 | -0.01 | -124.00 | -0.01 | -99.20 | Cycle 11, 2024-08-01 to 2025-11-30 |
This gives us the following data points:
- Cycle start date
- Cycle end date
- Number of months in the cycle
- Cumulative return during the cycle (decimal and percent)
- Average monthly return during the cycle (decimal and percent)
- Annualized return during the cycle (decimal and percent)
- Return volatility during the cycle
- Cumulative change in FFR during the cycle (decimal and basis points)
- Annualized change in FFR during the cycle (decimal and basis points)
From the above DataFrame, we can then plot the cumulative and annualized returns for each cycle in a bar chart. First, the cumulative returns:
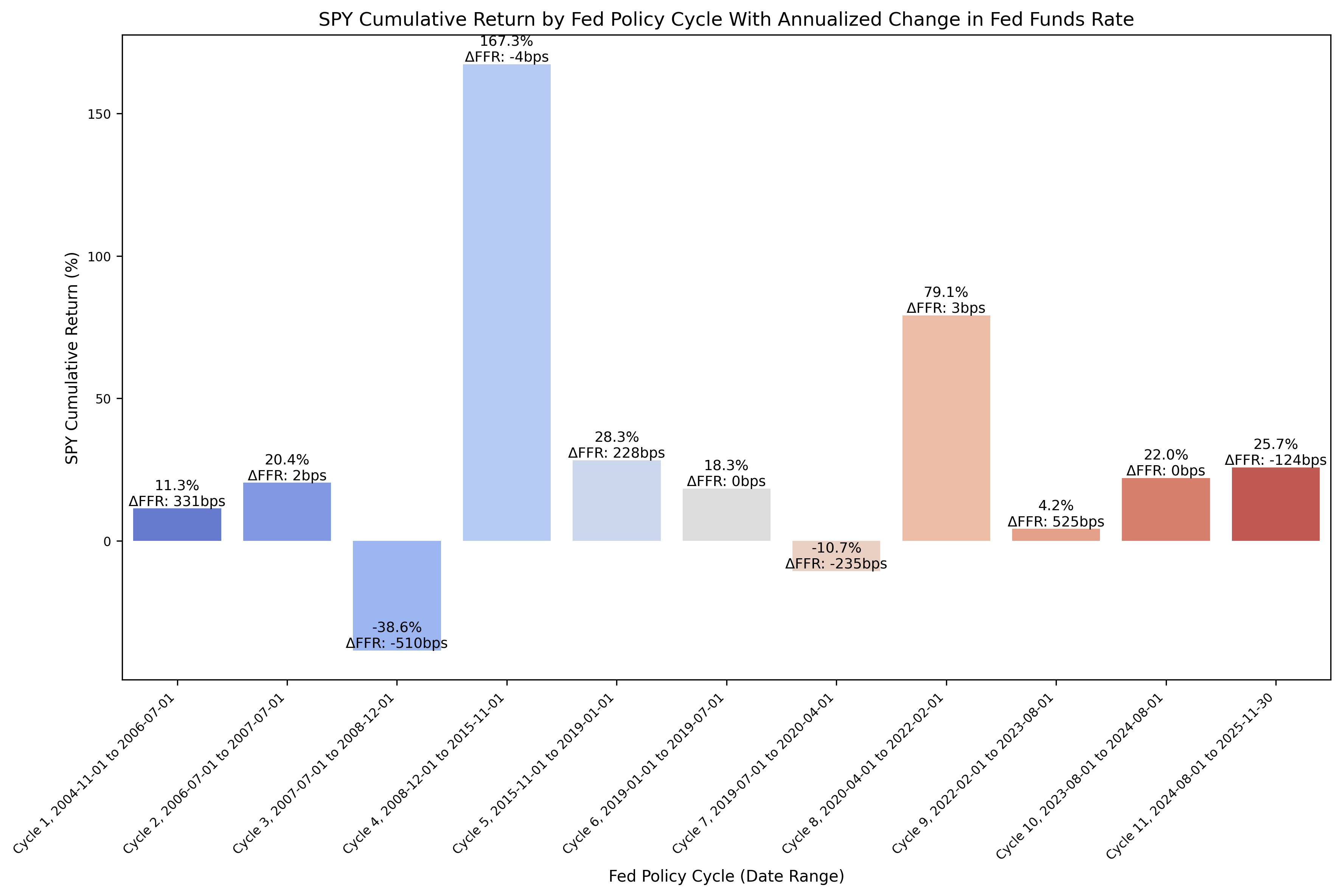
And then the annualized returns:
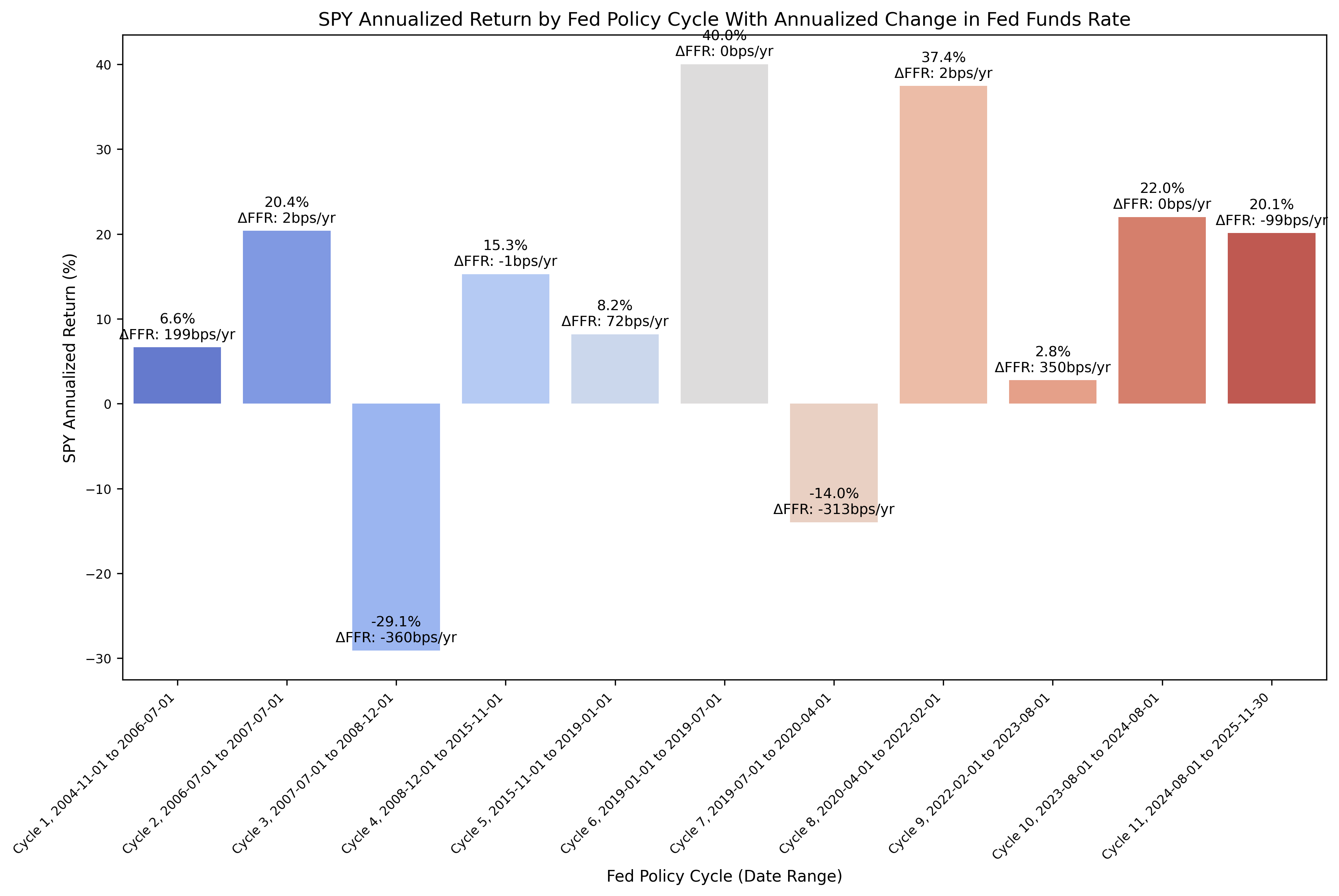
The cumulative returns plot is not particularly insightful, but there are some interesting observations to be gained from the annualized returns plot. During the past two (2) rate cutting cycles (cycles 3 and 7), the stocks have exhibited negative returns during the rate cutting cycle. However, after the rate cutting cycle was complete, the following returns were quite strong and higher than the historical mean return for the S&P 500. The economic intuition for this behavior is valid; as the economy weakens, the stock market falls, the returns become negative, and the Fed responds with cutting rates.
Finally, we can run an OLS regression to check fit:
| |
Which gives us the results of the OLS regression:
| |
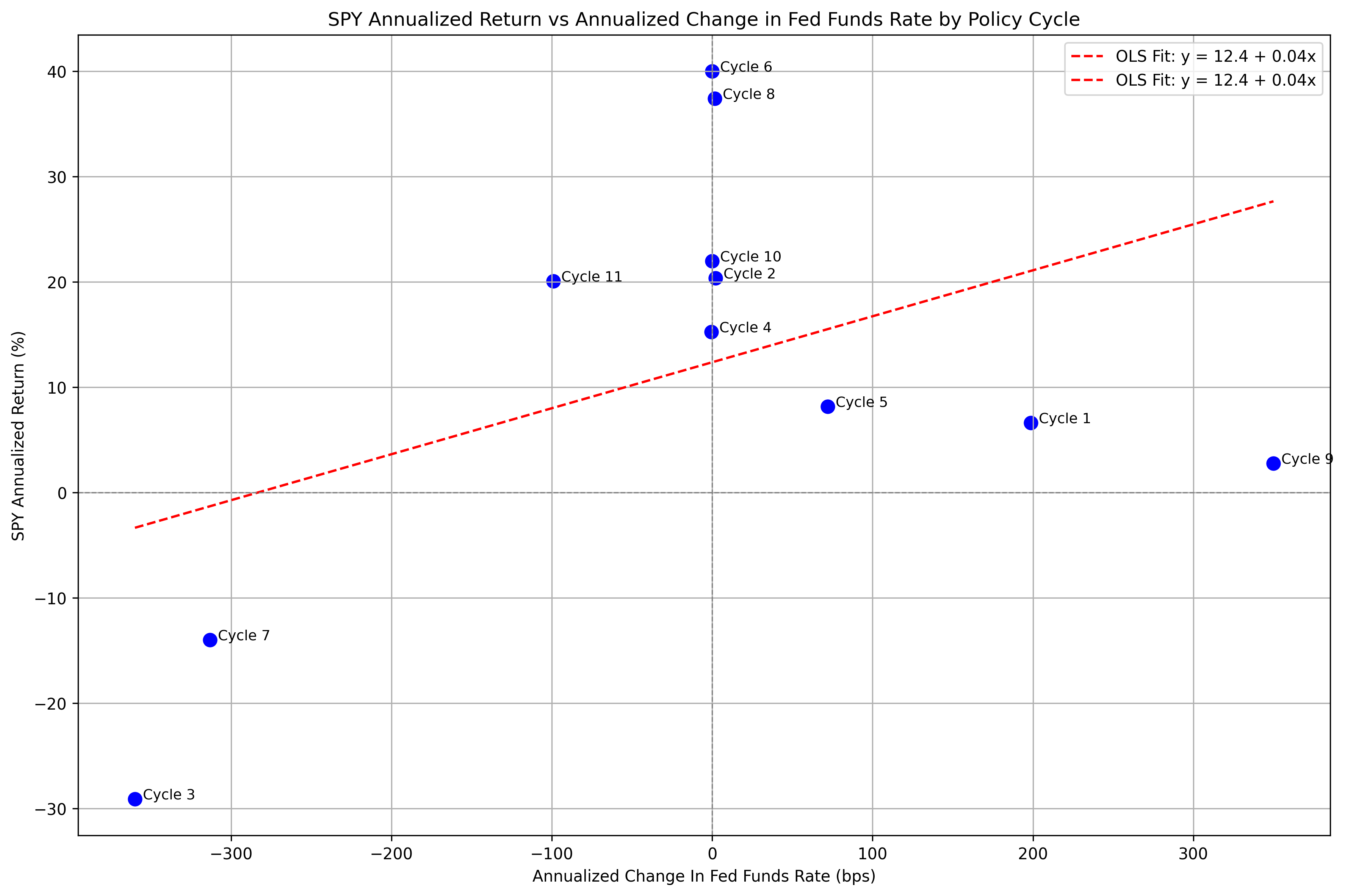
And then plot the regression line along with the values:
| |
Which gives us:
Bonds (TLT)
Next, we’ll run a similar process for long term bonds using TLT as the proxy.
First, we pull data with the following:
| |
And then load data with the following:
| |
Gives us the following:
| |
The first 5 rows are:
| Date | Close | High | Low | Open | Volume | Monthly_Return |
|---|---|---|---|---|---|---|
| 2004-11-30 00:00:00 | 44.13 | 44.24 | 43.97 | 44.13 | 1754500.00 | nan |
| 2004-12-31 00:00:00 | 45.30 | 45.35 | 45.17 | 45.21 | 1056400.00 | 0.03 |
| 2005-01-31 00:00:00 | 46.92 | 46.94 | 46.70 | 46.72 | 1313900.00 | 0.04 |
| 2005-02-28 00:00:00 | 46.22 | 46.78 | 46.16 | 46.78 | 2797300.00 | -0.01 |
| 2005-03-31 00:00:00 | 46.01 | 46.05 | 45.77 | 45.95 | 2410900.00 | -0.00 |
The last 5 rows are:
| Date | Close | High | Low | Open | Volume | Monthly_Return |
|---|---|---|---|---|---|---|
| 2025-06-30 00:00:00 | 86.64 | 86.83 | 86.01 | 86.26 | 53695200.00 | 0.03 |
| 2025-07-31 00:00:00 | 85.65 | 86.14 | 85.57 | 85.86 | 49814100.00 | -0.01 |
| 2025-08-31 00:00:00 | 85.66 | 85.92 | 85.51 | 85.82 | 41686400.00 | 0.00 |
| 2025-09-30 00:00:00 | 88.74 | 89.40 | 88.58 | 89.03 | 38584000.00 | 0.04 |
| 2025-10-31 00:00:00 | 89.96 | 90.33 | 89.88 | 90.23 | 38247300.00 | 0.01 |
Next, we can plot the price history before calculating the cycle performance:
| |
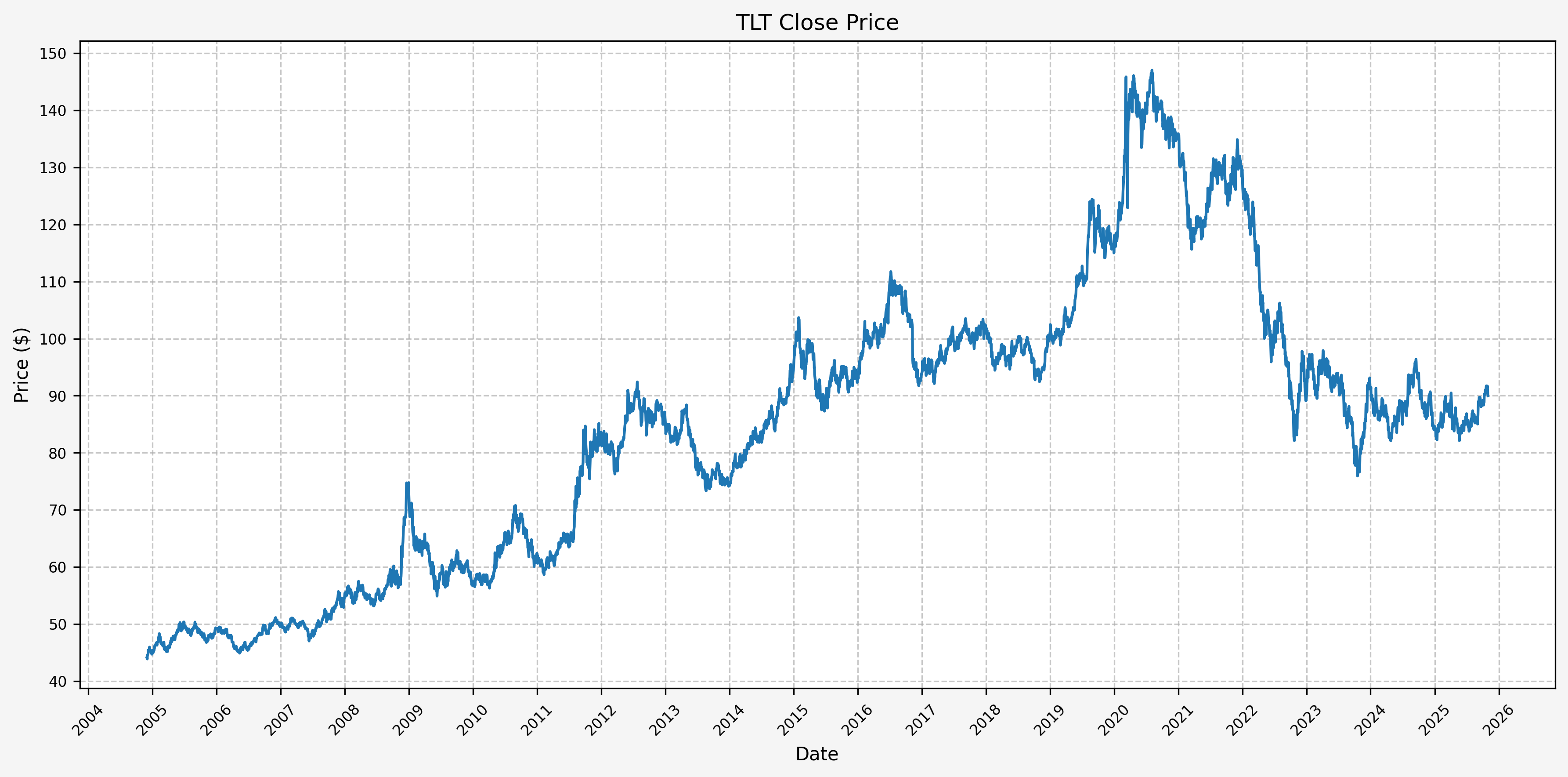
Next, we will calculate the performance for SPY based on the pre-defined Fed cycles:
| |
Which gives us:
| Cycle | Start | End | Months | CumulativeReturn | CumulativeReturnPct | AverageMonthlyReturn | AverageMonthlyReturnPct | AnnualizedReturn | AnnualizedReturnPct | Volatility | FedFundsChange | FedFundsChange_bps | FFR_AnnualizedChange | FFR_AnnualizedChange_bps | Label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Cycle 1 | 2004-11-01 | 2006-07-01 | 20 | 0.04 | 4.23 | 0.00 | 0.25 | 0.03 | 2.51 | 0.09 | 0.03 | 331.00 | 0.02 | 198.60 | Cycle 1, 2004-11-01 to 2006-07-01 |
| 1 | Cycle 2 | 2006-07-01 | 2007-07-01 | 12 | 0.06 | 5.76 | 0.00 | 0.49 | 0.06 | 5.76 | 0.07 | 0.00 | 2.00 | 0.00 | 2.00 | Cycle 2, 2006-07-01 to 2007-07-01 |
| 2 | Cycle 3 | 2007-07-01 | 2008-12-01 | 17 | 0.32 | 32.42 | 0.02 | 1.73 | 0.22 | 21.92 | 0.14 | -0.05 | -510.00 | -0.04 | -360.00 | Cycle 3, 2007-07-01 to 2008-12-01 |
| 3 | Cycle 4 | 2008-12-01 | 2015-11-01 | 83 | 0.46 | 45.67 | 0.01 | 0.55 | 0.06 | 5.59 | 0.15 | -0.00 | -4.00 | -0.00 | -0.58 | Cycle 4, 2008-12-01 to 2015-11-01 |
| 4 | Cycle 5 | 2015-11-01 | 2019-01-01 | 38 | 0.07 | 7.42 | 0.00 | 0.23 | 0.02 | 2.29 | 0.10 | 0.02 | 228.00 | 0.01 | 72.00 | Cycle 5, 2015-11-01 to 2019-01-01 |
| 5 | Cycle 6 | 2019-01-01 | 2019-07-01 | 6 | 0.10 | 10.48 | 0.02 | 1.73 | 0.22 | 22.05 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | Cycle 6, 2019-01-01 to 2019-07-01 |
| 6 | Cycle 7 | 2019-07-01 | 2020-04-01 | 9 | 0.26 | 26.18 | 0.03 | 2.73 | 0.36 | 36.34 | 0.18 | -0.02 | -235.00 | -0.03 | -313.33 | Cycle 7, 2019-07-01 to 2020-04-01 |
| 7 | Cycle 8 | 2020-04-01 | 2022-02-01 | 22 | -0.11 | -11.33 | -0.00 | -0.50 | -0.06 | -6.35 | 0.11 | 0.00 | 3.00 | 0.00 | 1.64 | Cycle 8, 2020-04-01 to 2022-02-01 |
| 8 | Cycle 9 | 2022-02-01 | 2023-08-01 | 18 | -0.27 | -26.96 | -0.02 | -1.62 | -0.19 | -18.90 | 0.17 | 0.05 | 525.00 | 0.03 | 350.00 | Cycle 9, 2022-02-01 to 2023-08-01 |
| 9 | Cycle 10 | 2023-08-01 | 2024-08-01 | 12 | -0.02 | -1.52 | 0.00 | 0.02 | -0.02 | -1.52 | 0.20 | 0.00 | 0.00 | 0.00 | 0.00 | Cycle 10, 2023-08-01 to 2024-08-01 |
| 10 | Cycle 11 | 2024-08-01 | 2025-11-30 | 15 | 0.00 | 0.42 | 0.00 | 0.08 | 0.00 | 0.33 | 0.11 | -0.01 | -124.00 | -0.01 | -99.20 | Cycle 11, 2024-08-01 to 2025-11-30 |
This gives us the following data points:
- Cycle start date
- Cycle end date
- Number of months in the cycle
- Cumulative return during the cycle (decimal and percent)
- Average monthly return during the cycle (decimal and percent)
- Annualized return during the cycle (decimal and percent)
- Return volatility during the cycle
- Cumulative change in FFR during the cycle (decimal and basis points)
- Annualized change in FFR during the cycle (decimal and basis points)
From the above DataFrame, we can then plot the cumulative and annualized returns for each cycle in a bar chart. First, the cumulative returns:
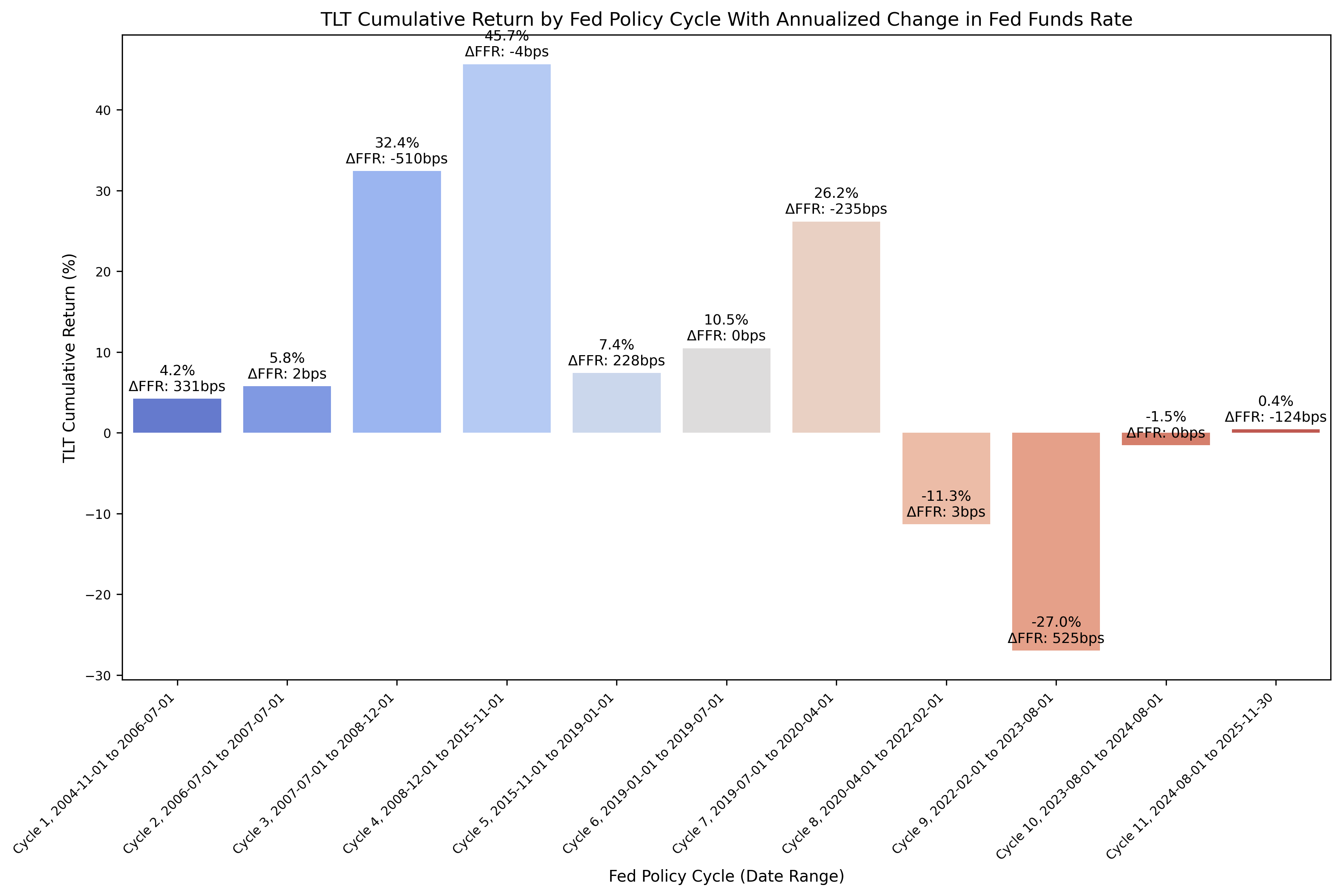
And then the annualized returns:
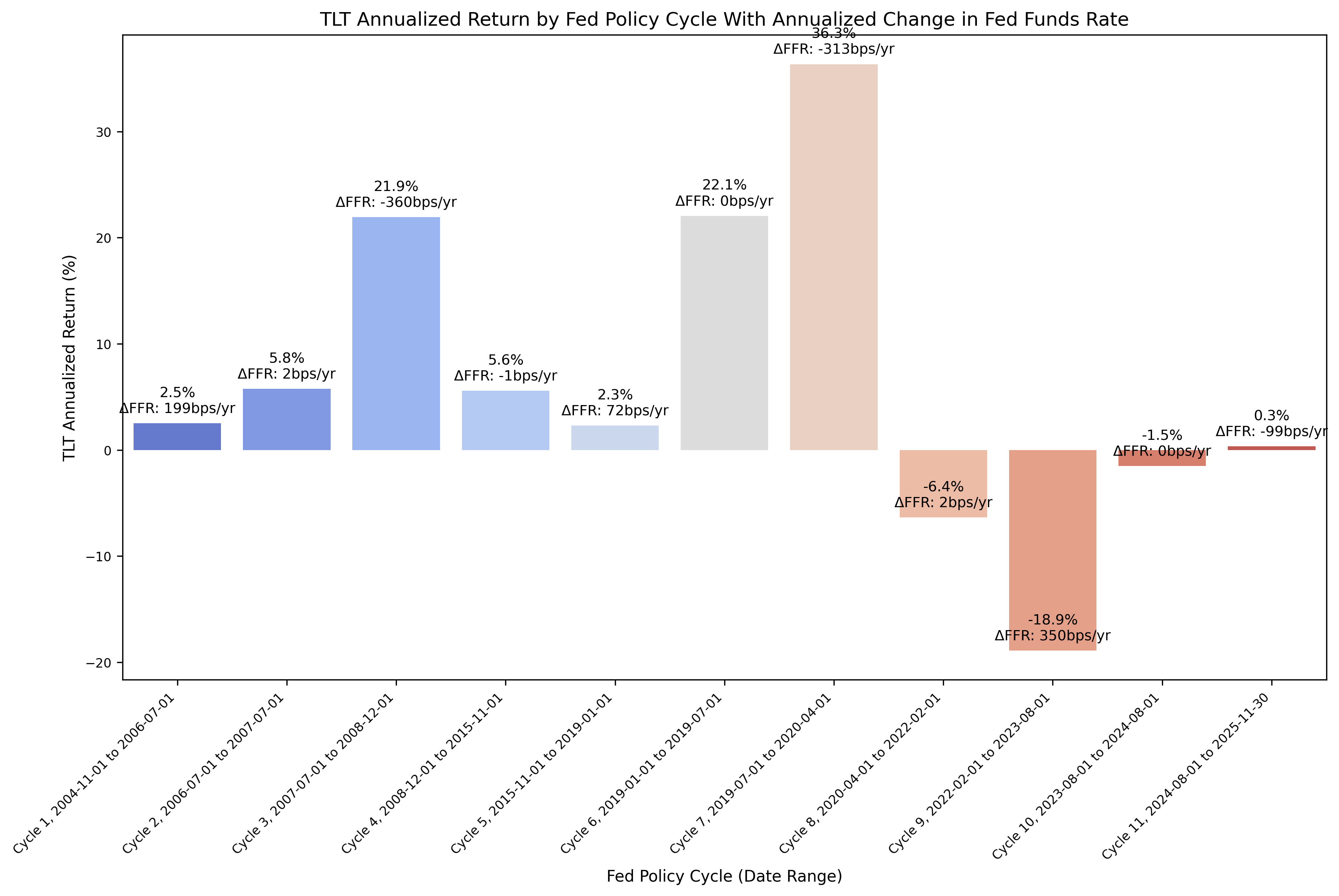
Let’s focus our analysis on the plot comparing the annualized returns for TLT to the change in FFR. We can see that during cycles 3 and 7, the returns were very strong along with a rapid pace in cutting rates. During cycle 9, we see the opposite behavior, where as rates were increased the bond returns were very poor. The question for cycle 11, where bond returns have been essentially flat - is the pace of rate cuts not significant enough to benefit the bond market? Are there other factors at play that are influencing the long term bond returns? Keep in mind that we are also working with 20 year treasuries as well, but we could consider running analysis on investment grade or high yield corporate bonds.
Finally, we can run an OLS regression with the following code:
| |
Which gives us the results of the OLS regression:
| |
And then plot the regression line along with the values:
| |
Which gives us:
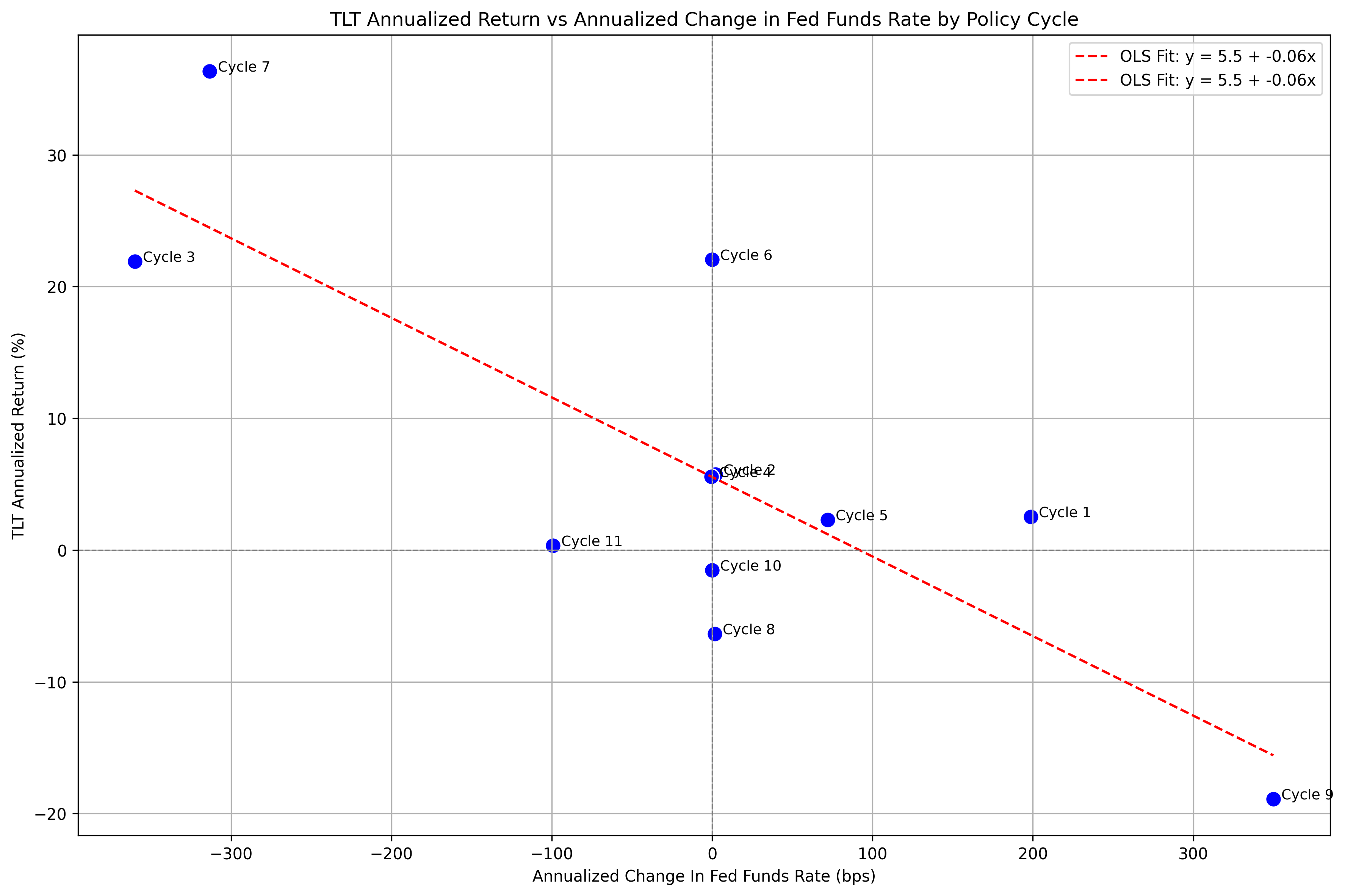
The above plot is intriguing because of how well the OLS regression appears to fit the data. It certainly appears that during rate-cutting cycles, bonds are an asset that performs well.
Gold (GLD)
Lastly, we’ll look at the returns on gold, using the GLD ETF as a proxy.
First, we pull data with the following:
| |
And then load data with the following:
| |
Gives us the following:
| |
The first 5 rows are:
| Date | Close | High | Low | Open | Volume | Monthly_Return |
|---|---|---|---|---|---|---|
| 2004-11-30 00:00:00 | 45.12 | 45.41 | 44.82 | 45.37 | 3857200.00 | nan |
| 2004-12-31 00:00:00 | 43.80 | 43.94 | 43.73 | 43.85 | 531600.00 | -0.03 |
| 2005-01-31 00:00:00 | 42.22 | 42.30 | 41.96 | 42.21 | 1692400.00 | -0.04 |
| 2005-02-28 00:00:00 | 43.53 | 43.74 | 43.52 | 43.68 | 755300.00 | 0.03 |
| 2005-03-31 00:00:00 | 42.82 | 42.87 | 42.70 | 42.87 | 1363200.00 | -0.02 |
The last 5 rows are:
| Date | Close | High | Low | Open | Volume | Monthly_Return |
|---|---|---|---|---|---|---|
| 2025-06-30 00:00:00 | 304.83 | 304.92 | 301.95 | 302.39 | 8192100.00 | 0.00 |
| 2025-07-31 00:00:00 | 302.96 | 304.61 | 302.86 | 304.59 | 8981000.00 | -0.01 |
| 2025-08-31 00:00:00 | 318.07 | 318.09 | 314.64 | 314.72 | 15642600.00 | 0.05 |
| 2025-09-30 00:00:00 | 355.47 | 355.57 | 350.87 | 351.13 | 13312400.00 | 0.12 |
| 2025-10-31 00:00:00 | 368.12 | 370.66 | 365.50 | 370.47 | 11077900.00 | 0.04 |
Next, we can plot the price history before calculating the cycle performance:
| |
Next, we will calculate the performance for SPY based on the pre-defined Fed cycles:
| |
Which gives us:
| Cycle | Start | End | Months | CumulativeReturn | CumulativeReturnPct | AverageMonthlyReturn | AverageMonthlyReturnPct | AnnualizedReturn | AnnualizedReturnPct | Volatility | FedFundsChange | FedFundsChange_bps | FFR_AnnualizedChange | FFR_AnnualizedChange_bps | Label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Cycle 1 | 2004-11-01 | 2006-07-01 | 20 | 0.36 | 35.70 | 0.02 | 1.73 | 0.20 | 20.10 | 0.17 | 0.03 | 331.00 | 0.02 | 198.60 | Cycle 1, 2004-11-01 to 2006-07-01 |
| 1 | Cycle 2 | 2006-07-01 | 2007-07-01 | 12 | 0.05 | 4.96 | 0.00 | 0.45 | 0.05 | 4.96 | 0.11 | 0.00 | 2.00 | 0.00 | 2.00 | Cycle 2, 2006-07-01 to 2007-07-01 |
| 2 | Cycle 3 | 2007-07-01 | 2008-12-01 | 17 | 0.25 | 24.96 | 0.02 | 1.59 | 0.17 | 17.03 | 0.26 | -0.05 | -510.00 | -0.04 | -360.00 | Cycle 3, 2007-07-01 to 2008-12-01 |
| 3 | Cycle 4 | 2008-12-01 | 2015-11-01 | 83 | 0.36 | 36.10 | 0.01 | 0.51 | 0.05 | 4.56 | 0.18 | -0.00 | -4.00 | -0.00 | -0.58 | Cycle 4, 2008-12-01 to 2015-11-01 |
| 4 | Cycle 5 | 2015-11-01 | 2019-01-01 | 38 | 0.11 | 10.93 | 0.00 | 0.35 | 0.03 | 3.33 | 0.14 | 0.02 | 228.00 | 0.01 | 72.00 | Cycle 5, 2015-11-01 to 2019-01-01 |
| 5 | Cycle 6 | 2019-01-01 | 2019-07-01 | 6 | 0.10 | 9.86 | 0.02 | 1.63 | 0.21 | 20.68 | 0.12 | 0.00 | 0.00 | 0.00 | 0.00 | Cycle 6, 2019-01-01 to 2019-07-01 |
| 6 | Cycle 7 | 2019-07-01 | 2020-04-01 | 9 | 0.11 | 11.15 | 0.01 | 1.24 | 0.15 | 15.13 | 0.13 | -0.02 | -235.00 | -0.03 | -313.33 | Cycle 7, 2019-07-01 to 2020-04-01 |
| 7 | Cycle 8 | 2020-04-01 | 2022-02-01 | 22 | 0.14 | 13.54 | 0.01 | 0.69 | 0.07 | 7.17 | 0.16 | 0.00 | 3.00 | 0.00 | 1.64 | Cycle 8, 2020-04-01 to 2022-02-01 |
| 8 | Cycle 9 | 2022-02-01 | 2023-08-01 | 18 | 0.08 | 8.48 | 0.01 | 0.53 | 0.06 | 5.58 | 0.14 | 0.05 | 525.00 | 0.03 | 350.00 | Cycle 9, 2022-02-01 to 2023-08-01 |
| 9 | Cycle 10 | 2023-08-01 | 2024-08-01 | 12 | 0.24 | 24.24 | 0.02 | 1.89 | 0.24 | 24.24 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | Cycle 10, 2023-08-01 to 2024-08-01 |
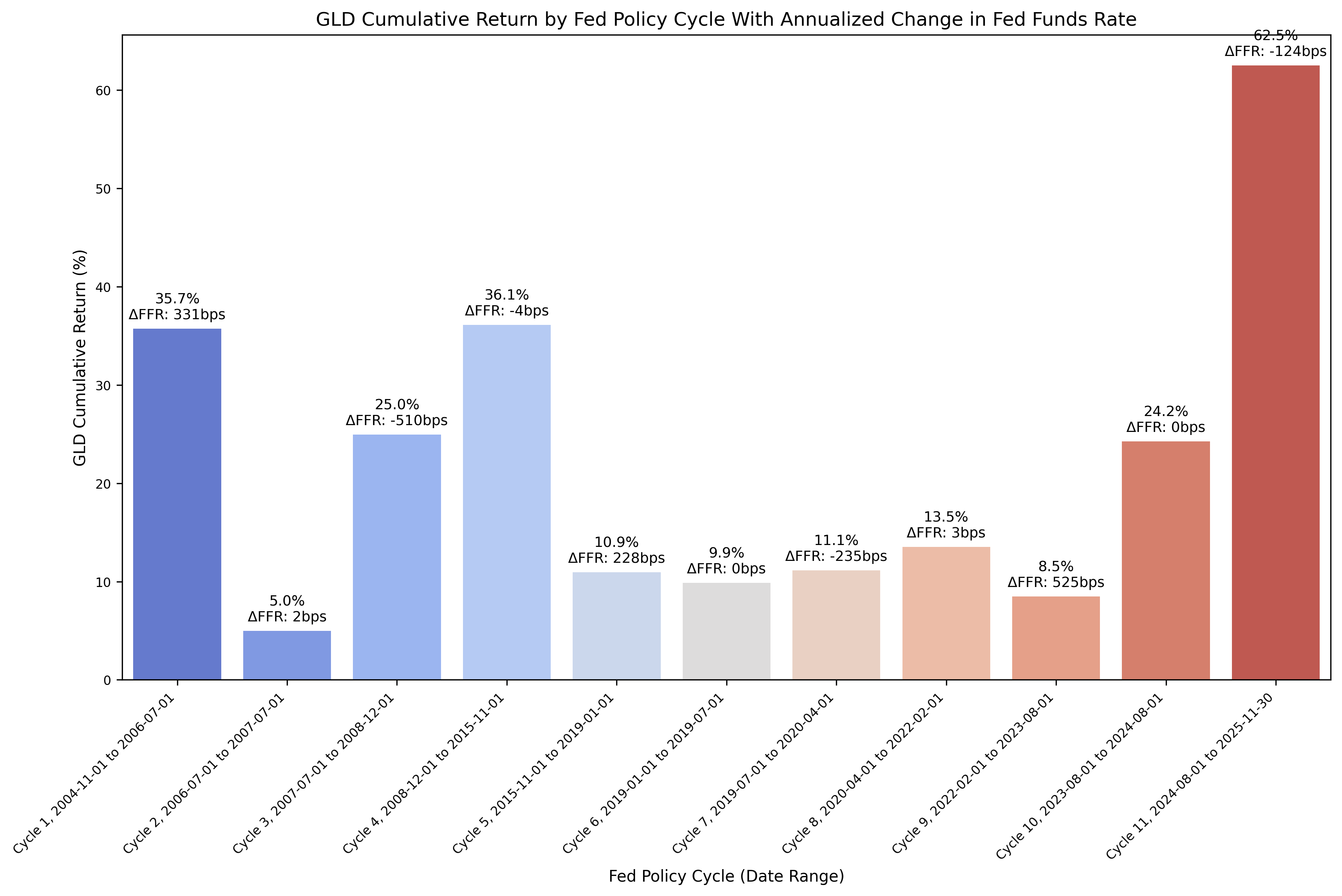
| 10 | Cycle 11 | 2024-08-01 | 2025-11-30 | 15 | 0.62 | 62.49 | 0.03 | 3.36 | 0.47 | 47.46 | 0.14 | -0.01 | -124.00 | -0.01 | -99.20 | Cycle 11, 2024-08-01 to 2025-11-30 |
This gives us the following data points:
- Cycle start date
- Cycle end date
- Number of months in the cycle
- Cumulative return during the cycle (decimal and percent)
- Average monthly return during the cycle (decimal and percent)
- Annualized return during the cycle (decimal and percent)
- Return volatility during the cycle
- Cumulative change in FFR during the cycle (decimal and basis points)
- Annualized change in FFR during the cycle (decimal and basis points)
From the above DataFrame, we can then plot the cumulative and annualized returns for each cycle in a bar chart. First, the cumulative returns:
And then the annualized returns:
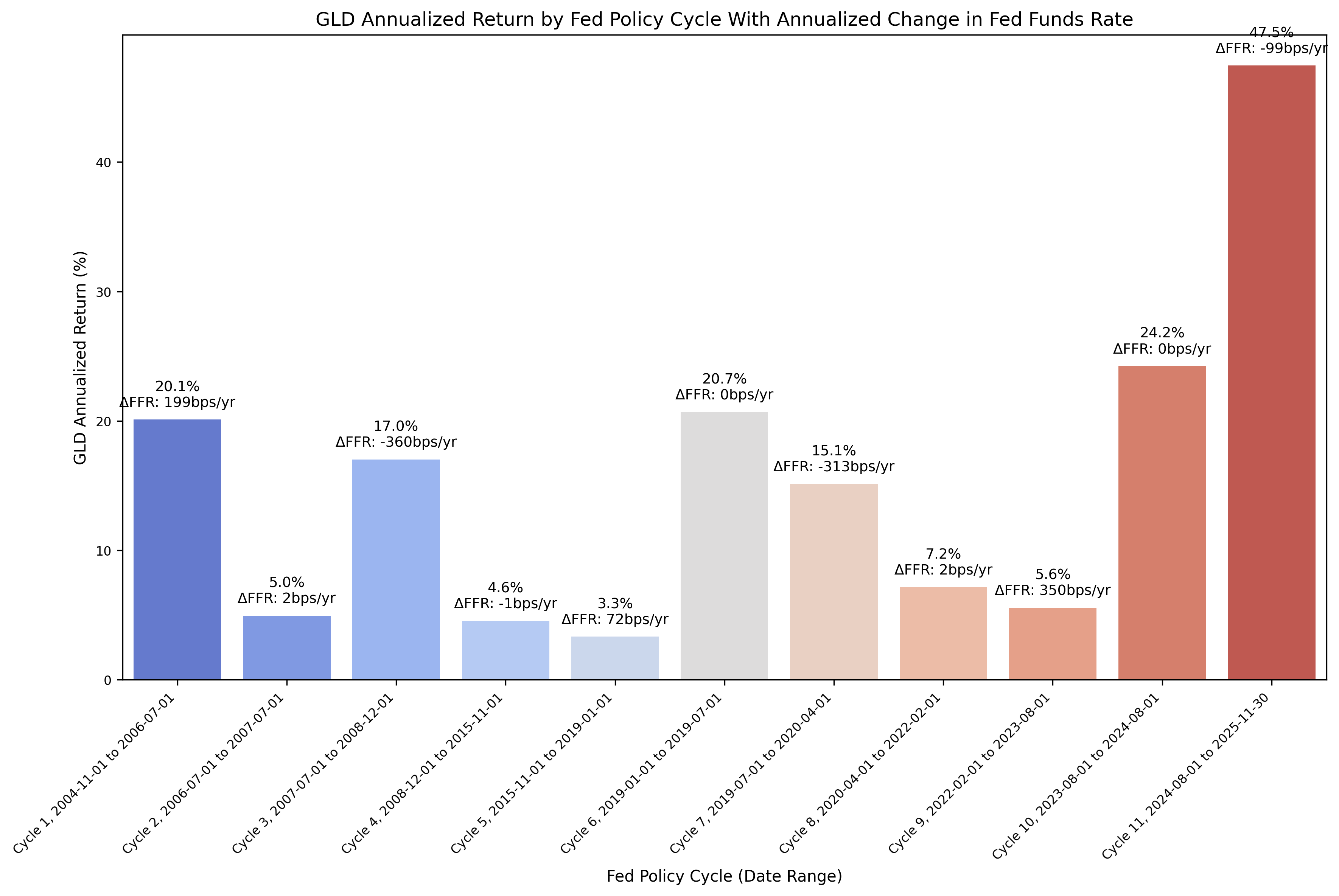
We see strong returns for gold across several different Fed cycles, so it is difficult to draw any kind of initial conclusion based on the bar charts.
Finally, we can run an OLS regression with the following code:
| |
Which gives us the results of the OLS regression:
| |
And then plot the regression line along with the values:
| |
Which gives us:
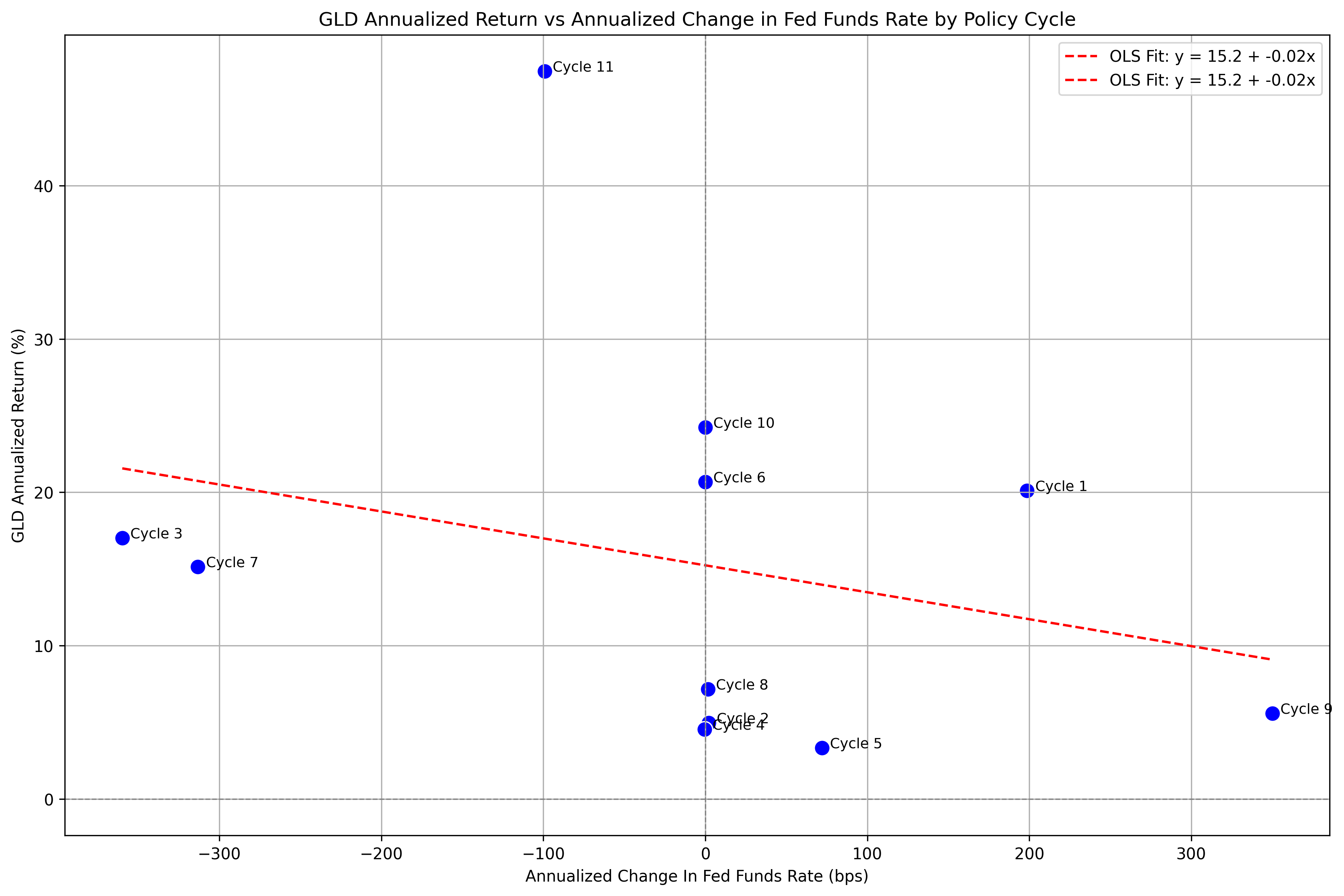
It’s difficult to draw any strong conclusions with the above plot. Gold has traditionally been considered a hedge for inflation, and while one of the Fed’s mandates is to manage inflation, there may not be a conclusion to draw in relationship to the historical returns that gold has exhibited.
Hybrid Portfolio
With the above analysis (somewhat) complete, let’s look at the optimal allocation for a portfolio based on the data and the hypythetical historical results.
Recall the plots for annualized returns vs annualized change in FFR for stocks, bonds, and gold:
Asset Allocation
We have to be careful with our criteria for when to hold stocks, bonds, or gold, as hindsight bias is certainly possible. So, without overanalyzing the results, let’s assume that we hold stocks as the default position, and then hold bonds when the Fed starts cutting rates, and then resume holding stocks when the Fed stops cutting rates. If there is not any change in FFR, then we still hold stocks. That gives us:
- Cycle 1: Stocks
- Cycle 2: Stocks
- Cycle 3: Bonds
- Cycle 4: Stocks
- Cycle 5: Stocks
- Cycle 6: Stocks
- Cycle 7: Bonds
- Cycle 8: Stocks
- Cycle 9: Stocks
- Cycle 10: Stocks
- Cycle 11: Bonds
We can then combine the return series based on the above with the following code:
| |
Which gives us:
| |
The first 5 rows are:
| Date | Portfolio_Monthly_Return | Portfolio_Cumulative_Return | Portfolio_Drawdown | SPY_Monthly_Return | SPY_Cumulative_Return | SPY_Drawdown | TLT_Monthly_Return | TLT_Cumulative_Return | TLT_Drawdown |
|---|---|---|---|---|---|---|---|---|---|
| 2004-11-30 00:00:00 | nan | nan | nan | nan | nan | nan | nan | nan | nan |
| 2004-12-31 00:00:00 | 0.030 | 0.030 | 0.000 | 0.030 | 0.030 | 0.000 | 0.027 | 0.027 | 0.000 |
| 2005-01-31 00:00:00 | -0.022 | 0.007 | -0.022 | -0.022 | 0.007 | -0.022 | 0.036 | 0.063 | 0.000 |
| 2005-02-28 00:00:00 | 0.021 | 0.028 | -0.002 | 0.021 | 0.028 | -0.002 | -0.015 | 0.048 | -0.015 |
| 2005-03-31 00:00:00 | -0.018 | 0.009 | -0.020 | -0.018 | 0.009 | -0.020 | -0.005 | 0.043 | -0.019 |
The last 5 rows are:
| Date | Portfolio_Monthly_Return | Portfolio_Cumulative_Return | Portfolio_Drawdown | SPY_Monthly_Return | SPY_Cumulative_Return | SPY_Drawdown | TLT_Monthly_Return | TLT_Cumulative_Return | TLT_Drawdown |
|---|---|---|---|---|---|---|---|---|---|
| 2025-06-30 00:00:00 | 0.027 | 19.004 | -0.072 | 0.051 | 6.718 | 0.000 | 0.027 | 0.963 | -0.408 |
| 2025-07-31 00:00:00 | -0.011 | 18.776 | -0.082 | 0.023 | 6.896 | 0.000 | -0.011 | 0.941 | -0.415 |
| 2025-08-31 00:00:00 | 0.000 | 18.778 | -0.082 | 0.021 | 7.058 | 0.000 | 0.000 | 0.941 | -0.415 |
| 2025-09-30 00:00:00 | 0.036 | 19.489 | -0.049 | 0.036 | 7.345 | 0.000 | 0.036 | 1.011 | -0.394 |
| 2025-10-31 00:00:00 | 0.014 | 19.772 | -0.036 | 0.024 | 7.544 | 0.000 | 0.014 | 1.039 | -0.385 |
Next, we’ll look at performance for the assets and portfolio.
Performance Statistics
We can then plot the monthly returns:
And cumulative returns:
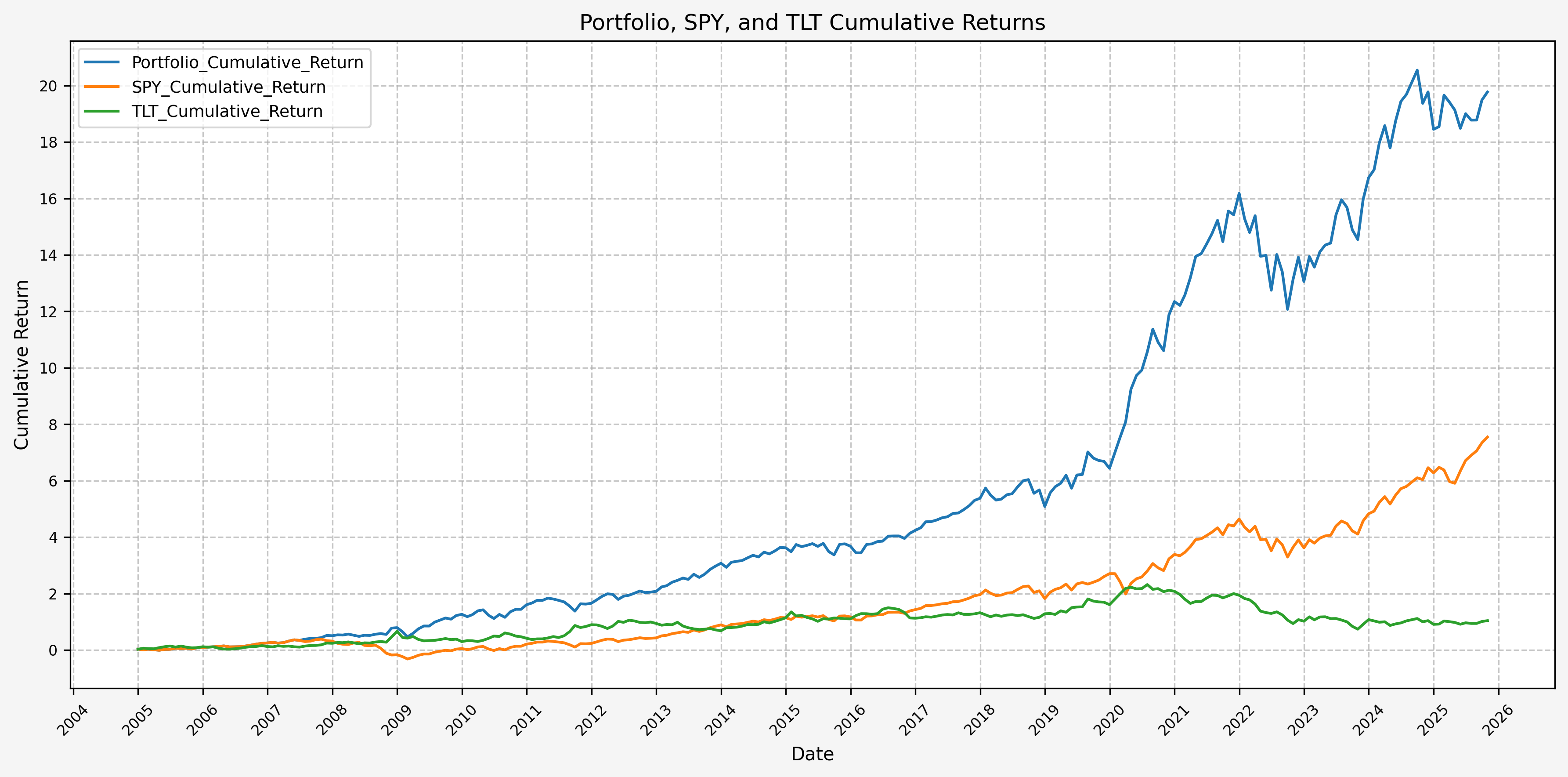
And drawdowns:
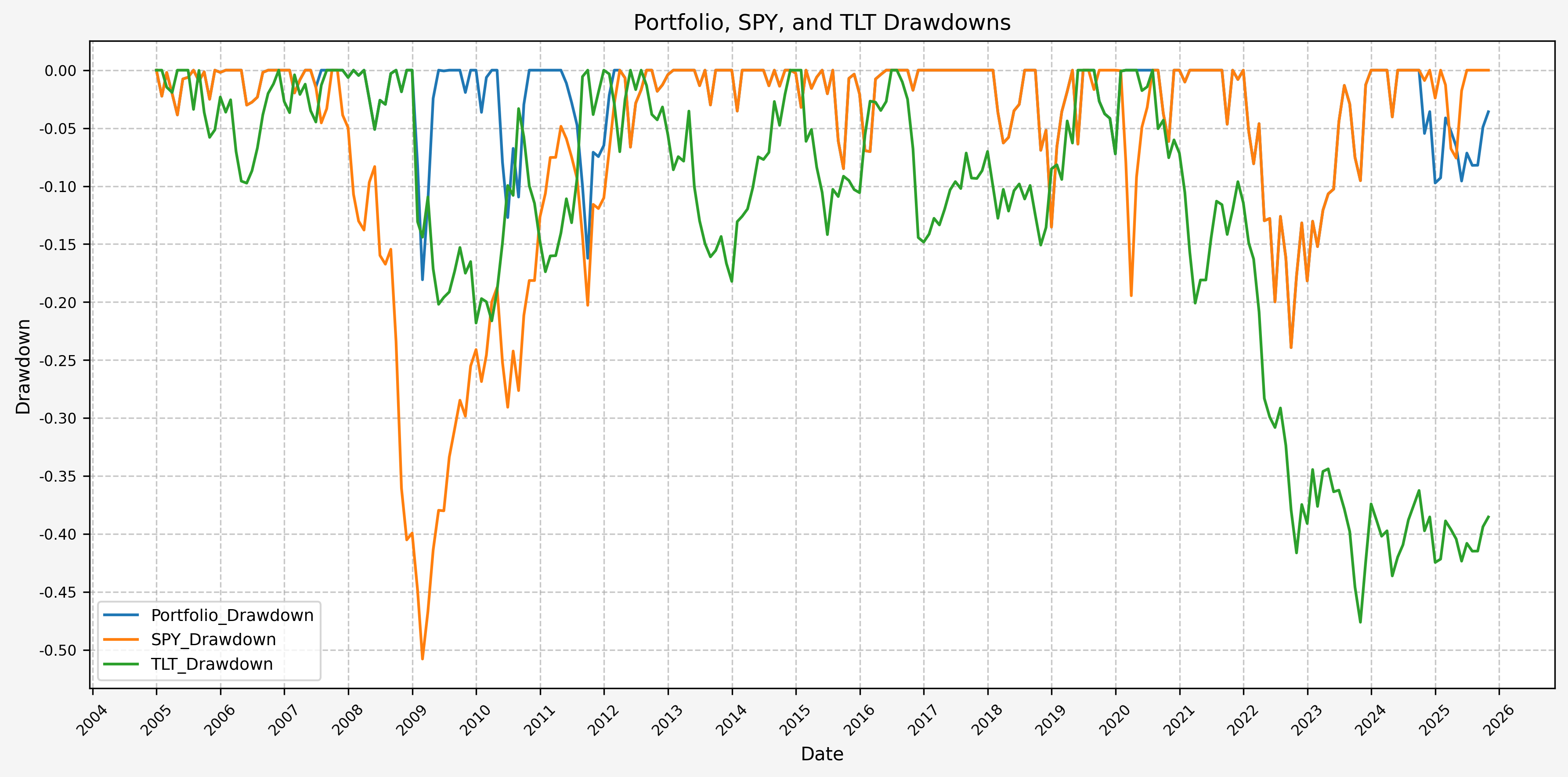
Finally, we can run the stats on the hybrid portfolio, SPY, and TLT with the following code:
| |
Which gives us:
| Annualized Mean | Annualized Volatility | Annualized Sharpe Ratio | CAGR | Monthly Max Return | Monthly Max Return (Date) | Monthly Min Return | Monthly Min Return (Date) | Max Drawdown | Peak | Trough | Recovery Date | Days to Recover | MAR Ratio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Portfolio_Monthly_Return | 0.156 | 0.140 | 1.111 | 0.155 | 0.143 | 2008-11-30 00:00:00 | -0.107 | 2009-02-28 00:00:00 | -0.239 | 2021-12-31 00:00:00 | 2022-09-30 00:00:00 | 2023-12-31 00:00:00 | 457.000 | 0.650 |
| SPY_Monthly_Return | 0.114 | 0.148 | 0.769 | 0.108 | 0.127 | 2020-04-30 00:00:00 | -0.165 | 2008-10-31 00:00:00 | -0.508 | 2007-10-31 00:00:00 | 2009-02-28 00:00:00 | 2012-03-31 00:00:00 | 1127.000 | 0.212 |
| TLT_Monthly_Return | 0.043 | 0.137 | 0.316 | 0.035 | 0.143 | 2008-11-30 00:00:00 | -0.131 | 2009-01-31 00:00:00 | -0.476 | 2020-07-31 00:00:00 | 2023-10-31 00:00:00 | NaT | nan | 0.072 |
Based on the above, our hybrid portfolio outperforms both stocks and bonds, and by a wide margin.
Future Investigation
A couple of ideas sound intriguing for future investigation:
- Do investment grade or high yield bonds show a different behavior than the long term US treasury bonds?
- Does a commodity index (such as GSCI) exhibit differing behavior than gold?
- How does leverage affect the returns that are observed for the hybrid portfolio, stocks, and bonds?
- Do other Fed tightening/loosening cycles exhibit the same behavior for returns?
References
Code
The jupyter notebook with the functions and all other code is available here.The html export of the jupyter notebook is available here.The pdf export of the jupyter notebook is available here.