
Introduction
In this tutorial, we will write a python function that imports an excel export from Bloomberg, removes ancillary rows and columns, and leaves the data in a format where it can then be used in time series analysis.
Example of a Bloomberg excel export
We will use the SPX index data in this example. Exporting the data from Bloomberg using the excel Bloomberg add-on yields data in the following format:
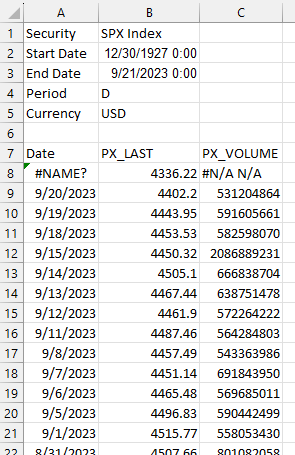
Data modifications
The above format isn’t horrible, but we want to perform the following modifications:
- Remove the first six rows of the data
- Convert the 7th row to become column headings
- Rename column 2 to “Close” to represent the closing price
- Remove column 3, as we are not concerned about volume
- Export to excel and make the name of the excel worksheet “data”
Assumptions
The remainder of this tutorial assumes the following:
- Your excel file is named “SPX_Index.xlsx”
- The worksheet in the excel file is named “Worksheet”
- You have the pandas library installed
- You have the OpenPyXL library installed
Python function to modify the data
The following function will perform the modifications mentioned above:
| |
Let’s break this down line by line.
Imports
First, we need to import pandas:
| |
Import excel data file
Then import the excel file as a pandas dataframe:
| |
Running:
df.head(10)
Gives us:
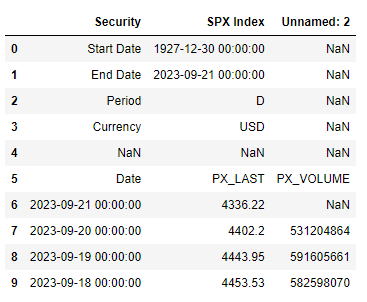
Set column headings
Next, set the column heading:
| |
Now, running:
df.head(10)
Gives us:
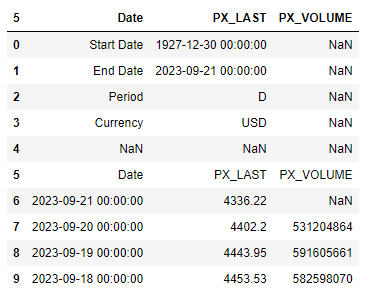
Remove index heading
Next, remove the column heading from the index column:
| |
Note: The axis=1 argument here specifies the column index.
Now, running:
df.head(10)
Gives us:
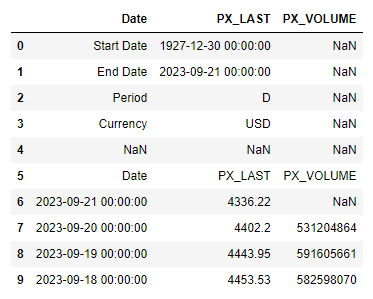
Drop rows
Next, we want to remove the first 6 rows that have unneeded data:
| |
Note: When dropping rows, the range to drop begins with row 0 and continues up to - but not including - row 6.
Now, running:
df.head(10)
Gives us:
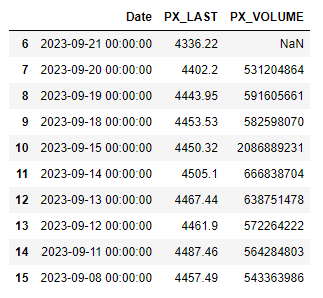
Set index
Next, we want to set the date column as the index:
| |
Now, running:
df.head(10)
Gives us:
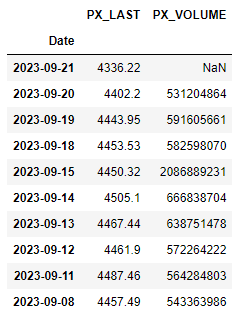
Drop the “PX_VOLUME” column
Next, we want to drop the volume column:
| |
For some data records, the volume column does not exist. Therefore, we try, and if it fails with a KeyError, then we assume the “PX_VOLUME” column does not exist, and just pass to move on.
Now, running:
df.head(10)
Gives us:
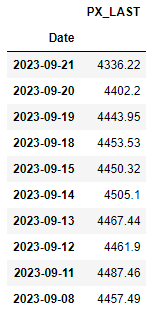
Rename the “PX_LAST” column
Next, we want to rename the “PX_LAST” column as “Close”:
| |
Now, running:
df.head(10)
Gives us:
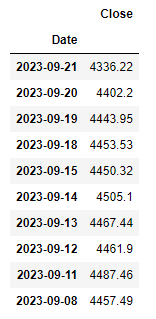
Sort data
Next, we want to sort the data starting with the oldest date:
| |
Now, running:
df.head(10)
Gives us:
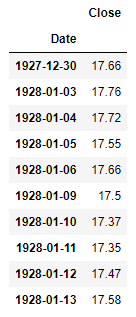
Export data
Next, we want to export the data to an excel file, for easy viewing and reference later:
| |
And verify the output is as expected:
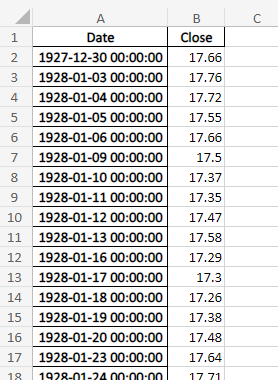
Output confirmation
Finally, we want to print a confirmation that the process succeeded along withe last date we have for data:
| |
And confirming the output:
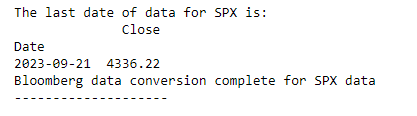
References
https://www.bloomberg.com/professional/support/software-updates/